
Team Members
-
Dr. Sarma Vrudhula (PI, Arizona State University)
-
Dr. Marwan Krunz (Co-PI, Univ. of Arizona)
-
Dr. Sanmukh Kuppannagari (Co-PI, Case Western Reserve University)
-
Dr. Gian Singh (post-doc, Arizona State University)
-
Ayushi Dube (Ph.D. Student, Arizona State University)
-
Abhinav Kumar (Master's Student, Arizona State University)
-
Sampad Chowdhury (Ph.D. Student, Arizona State University)
-
Arush Sharma (Ph.D. Student, Univ. of Arizona)
-
Rajan Shrestha (Ph.D. Student, Univ. of Arizona)
-
Changxin Li (Ph.D. Student, Case Reserve Western University)
Goals and Objectives
Deep neural networks (DNNs) have been successfully applied in many domains, including image classification, language models, speech analysis, autonomous vehicles, wireless communications, bioinformatics, and others. Their success stems from their ability to handle vast amounts of data and infer patterns without making assumptions on the underlying dynamics that produced the data. Cloud providers operate large data centers with high-speed computers that continuously perform DNN computations, with huge energy consumption that rivals that of some industries and nations. In addition to being used in solving large-scale problems, DNNs have recently been considered for recognition applications in battery-operated systems such as smartphones and embedded devices. However, there is a critical need to improve the energy efficiency of DNNs. The main goal of this project is twofold: (1) Design and evaluate a radically innovative energy-efficient hardware/software framework for on-chip implementation of DNNs, and (2) customize this framework for new DNNs that enable real-time signal classification in next-generation wireless systems. By integrating processing elements within memory chips, the energy consumption of a DNN can be significantly reduced, and more computations can be done faster. The hardware-accelerated DNN designs provided by this project will facilitate rapid identification of wireless transmissions (e.g. radar, 5G, LTE, Wi-Fi, microwave, satellite, and others) in a shared-spectrum scenario, enabling better use of the spectrum and facilitating accurate detection of adversarial and rogue signals. To achieve 10x-100x reduction in DNN energy consumption, a holistic approach is being pursued, which encompasses: (1) new circuit designs that leverage emerging ‘CMOS+X’ technologies; (2) a novel near-memory architecture in which processing elements are seamlessly integrated with traditional Dynamic RAM (DRAM); (3) novel 3D-matrix-based per-layer DNN computations and data-layout optimizations for kernel weights; and (4) algorithms and hardware/software co-design tailored for near-real-time DNN-based signal classification in next-generation wireless systems. In addition to its research goals, the project has a comprehensive educational and outreach agendas.
Research Thrusts
Thrust 1: Hardware Innovations for AI Pipelines
The Memory Wall ProblemDNNs are both compute and memory-bound. The energy consumption of large amounts of data transfers due to the processor-memory bottleneck between the memory and processors makes executing DNNs on traditional von Neumann computing systems (i.e., pure software implementations) environmentally unsustainable. Current hardware accelerators for DNNs that supplement a Von-Neumann CPU with ASICs, FPGAs, or GPUs have not overcome the processor-memory bottleneck. Moreover, each is customized to accelerate a specific type of DNN. |
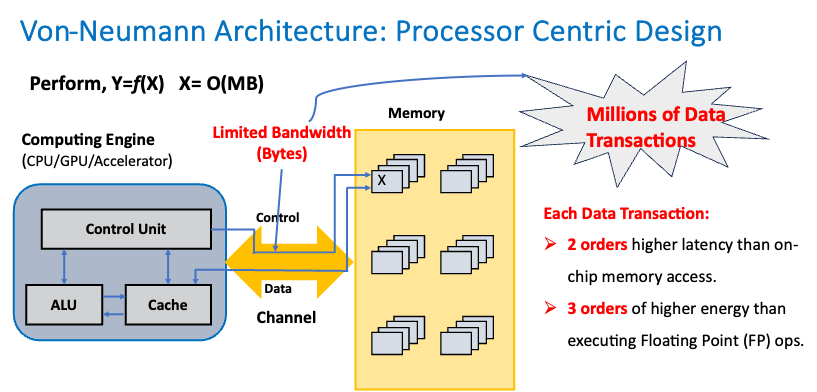
|
Processing in MemoryProcessing-in-Memory (PIM) or near-memory processor architectures have long been known as a solution to eliminate the processor-memory bottleneck. PIM architectures are a promising approach for achieving the necessary levels of improvement in energy efficiency for sustainability. We propose introducing the processing near DRAM memory arrays. DRAM is the primary choice of the main memory in computing systems. It has several significant advantages over the other types of emerging memories for PIM systems because of decades of continuous optimization of their devices, circuits, and architecture. The advantages include large capacity, high internal parallelism, high speed, and energy efficiency. |
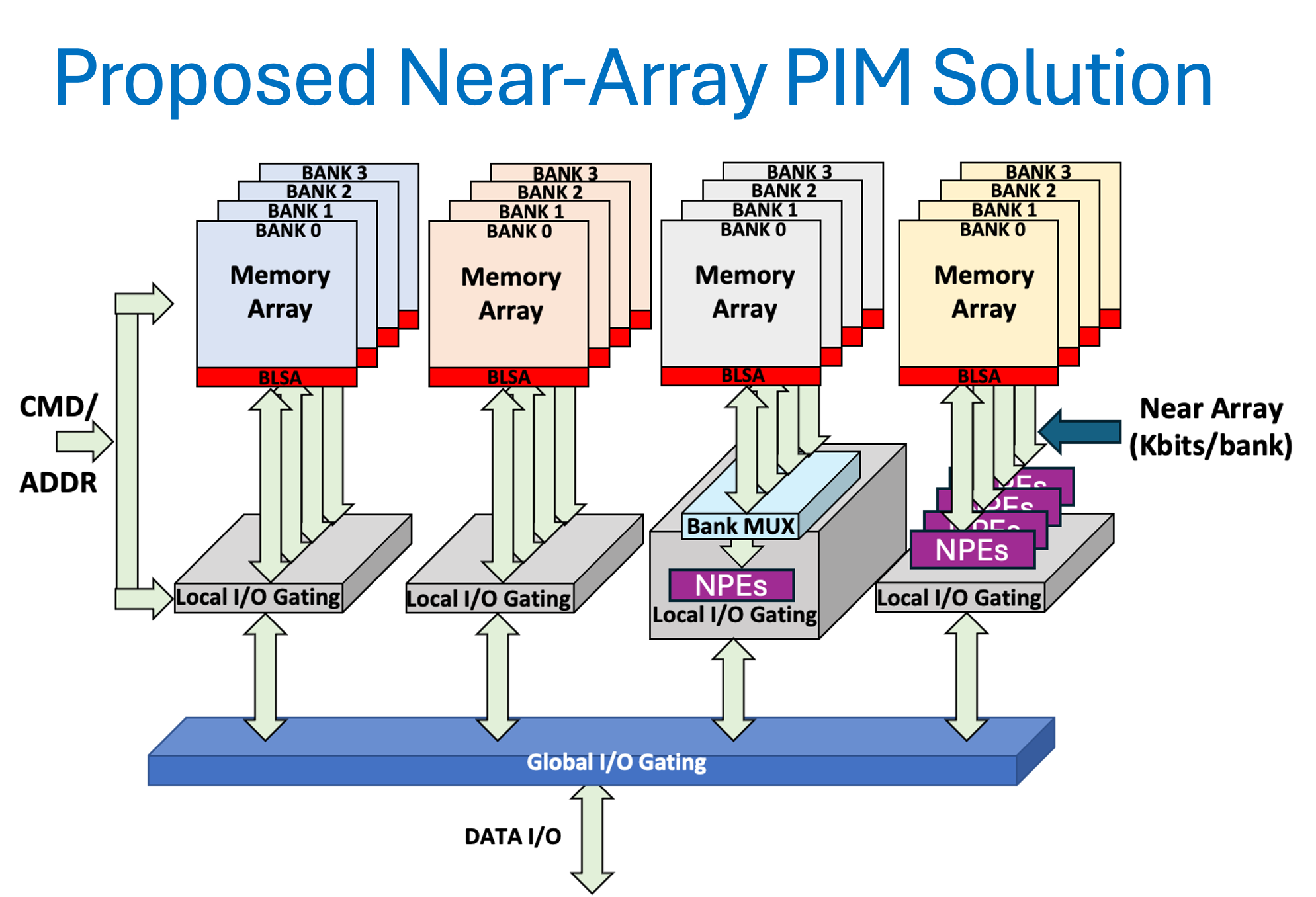
|
New Compute Elements (NPE and CMOS+X Neuron)This thrust of the project focuses on the co-design of devices, circuits, and near-memory processor architecture. It involves designing and optimizing a novel circuit architecture for a threshold logic gate (TLG) or Binary Neuron using CMOS and non-volatile programmable conductance devices (X) as shown in Figure. The key challenges are centered around developing algorithms for optimizing the CMOS and X parameters to achieve a robust TLG design in the presence of multiple sources of variations. We propose a new Neuron Processing Element (NPE), as shown in the Figure on the right, comprising a network of TLGs or configurable neurons (CNs), which will be designed to execute the essential neural network functions (inner products, activation functions, etc.). The NPE has several design parameters, including the number of clusters, the number and types of TLGs in each cluster, and the topology, which must be determined while optimizing for area, power, latency, throughput, and precision. |
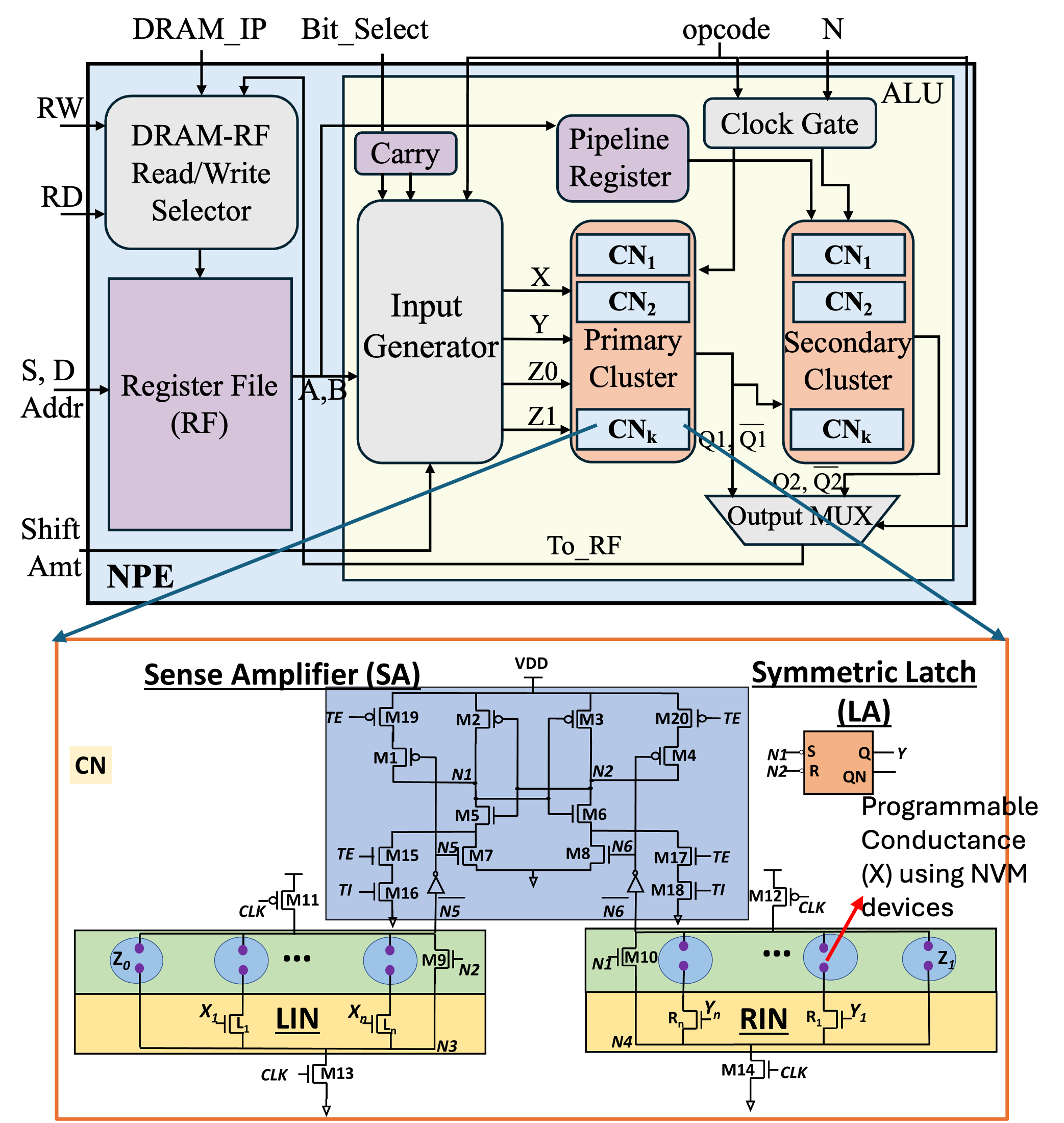
|
NPE-DRAM IntegrationThe NPEs are integrated with memory arrays (see the Figure on the Right) without interfering with the timing constraints or access protocols of the memory. This forms a single processor-in-memory system, which can be scaled to operate as a low-power edge device as well as a high-performance data center accelerator. |
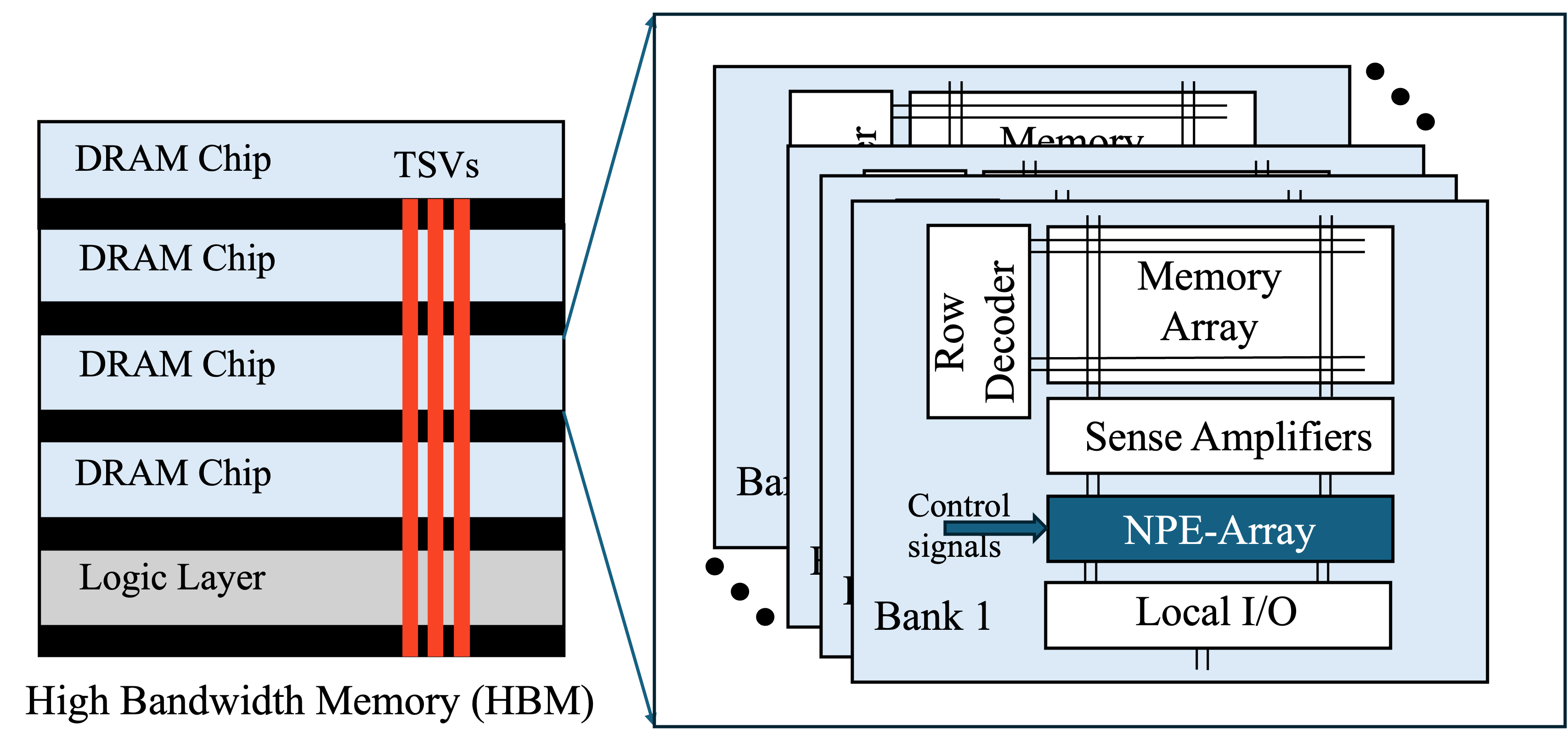
|
System IntegrationThe overall near-memory processor design includes integrating DRAM, NPE, and the host CPU. The host CPU is required to compile the DNN application, schedule the operations, and control the data flow between the DRAM and the CPU. To enable such integration, an interface of the DRAM in the form of an instruction set architecture (ISA) and the controller is required. To readily integrate HBMs with a host CPU, we propose the extensions to the host CPU (X86, ARM, or RISC-V) ISA called PIM+ ISA, to control the execution of the NPEs and the DRAM. The PIM+ ISA and the modifications to the CPU are also shown in the Figure. |
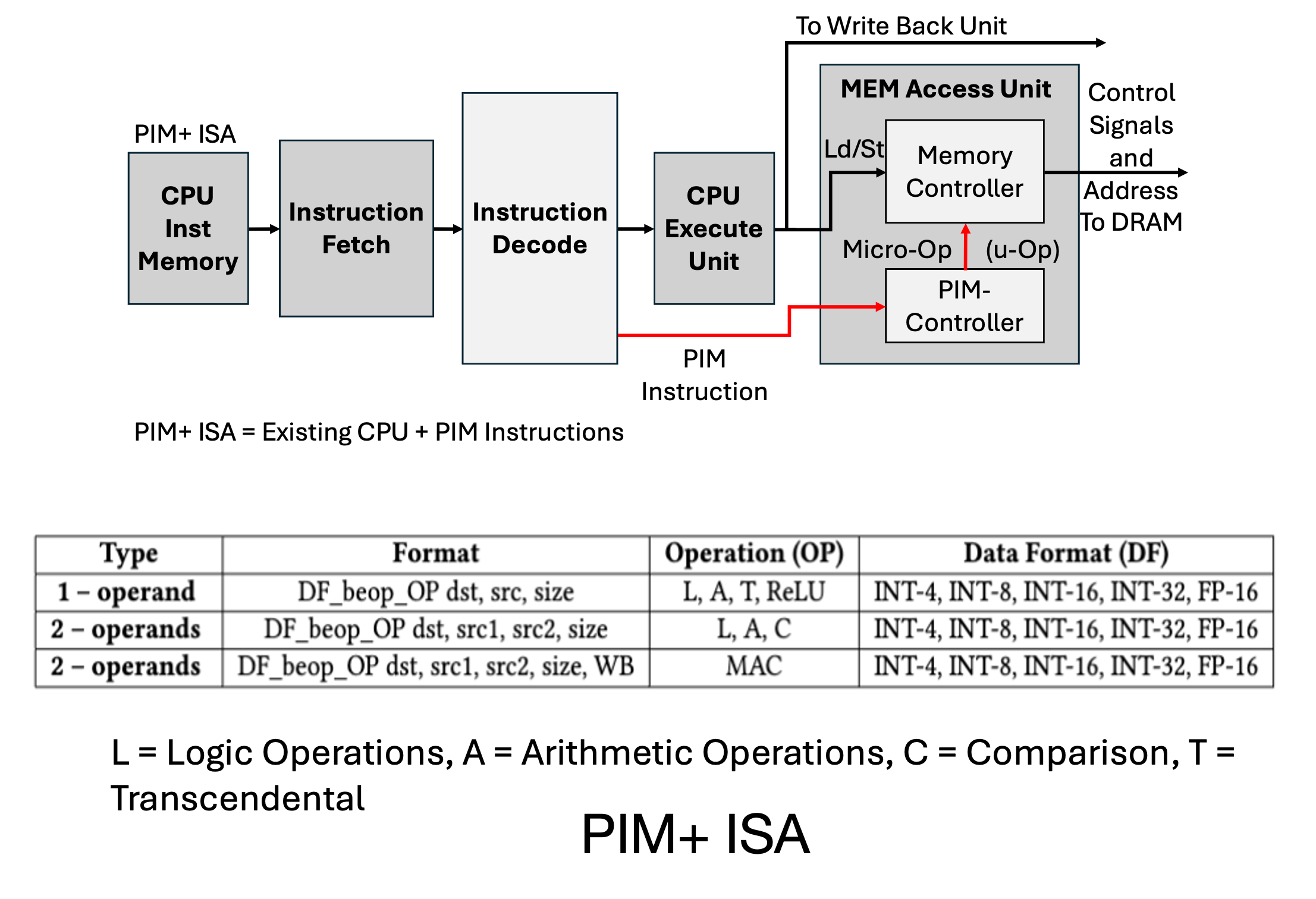
|
Sample Results:
The table and bar chart below show the result of computing the Transformer models BERT (small and large), BART (small and Large), and GPT-J on the proposed PIM architecture named CIDAN-3D. They show the throughput improvements of CIDAN-3D against three baseline PIM architectures: TransPIM (2022), HAIMA (2023), and NVIDIA V100 GPU. On average, CIDAN-3D achieved 21.5X throughput improvement over an NVIDIA GPU V100 with 8GB of memory. This advantage arises from the CIDAN’s efficient use of small NPEs interfaced with the row buffer outputs of DRAM banks, maximizing DRAM parallelism while minimizing high-latency DRAM operations like activate (ACT), read (RD), and write-back (WR). By performing all computations within DRAM, the proposed architecture avoids CPU-DRAM data transactions, significantly reducing latency and energy use.
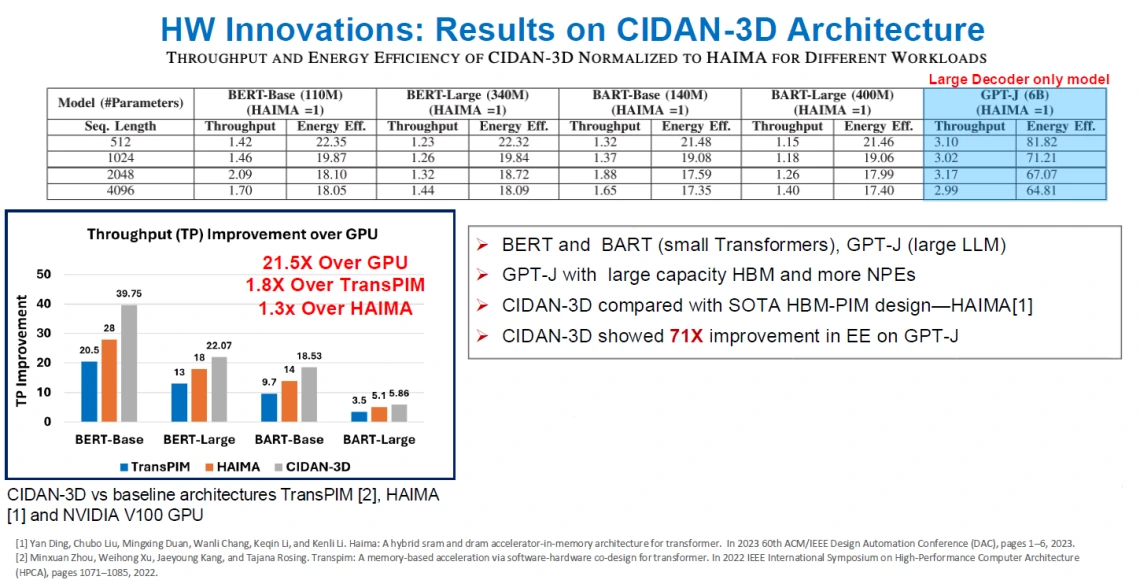
Next Steps:
- Demonstrate real-time inference on wireless signals in shared spectrum
- Fabricate compute elements in CMOS+FeFET
- New processor core for variable (INT, FP, POSIT) precision arithmetic
- Logic Neural Networks for low-power, real-time inference
Thrust 2: Software Acceleration (Optimized Mapping Tools)
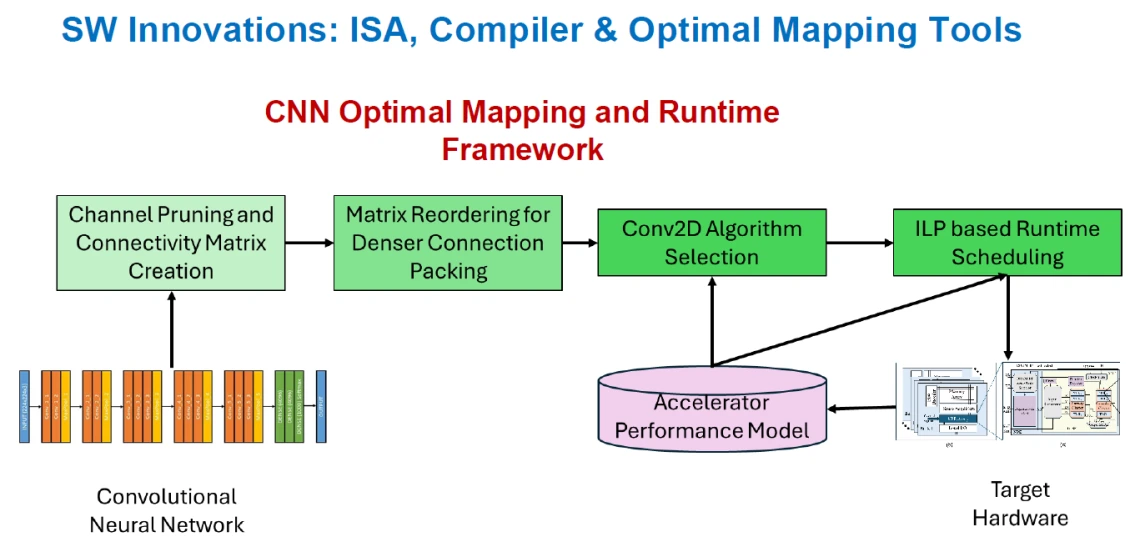
The objective of this thrust is to build a compilation and runtime toolkit to enable optimal mapping and execution of Wireless CNN applications (Thrust 3) on PIM AI accelerators (Thrust 1).
Our toolkit takes a CNN model and carefully introduces structured sparsity (channel pruning) to reduce the computations while achieving minimal reduction in accuracy. This structured sparse CNN is further optimized for mapping by creating a connectivity matrix to represent the active channels and using matrix reordering techniques to obtain denser packing of the active channels, as dense packing leads to more efficient hardware utilization. Using a performance model, that estimates the performance of a convolution algorithm mapped to a hardware platform, the toolkit selects a convolution algorithm that is expected to perform the best for the model and uses an Integer Program based runtime scheduling algorithm that partitions the active channels into buckets and schedules the buckets on the hardware.
For an example wireless application of Jamming detection using CNNs, our toolkit achieved up to 1.2 to 1.6x reduction in inference latency with an accuracy loss of less than 2% on a GPU platform compared to a Pytorch implementation. Our next steps include performance modeling and optimization on the PIM AI accelerator (Thrust 1), development of 3D convolution algorithms for multi-stage protocol classification, and end to end Pytorch PIM compilation framework to seamlessly support wireless application deployment on PIM.
Sample Results:
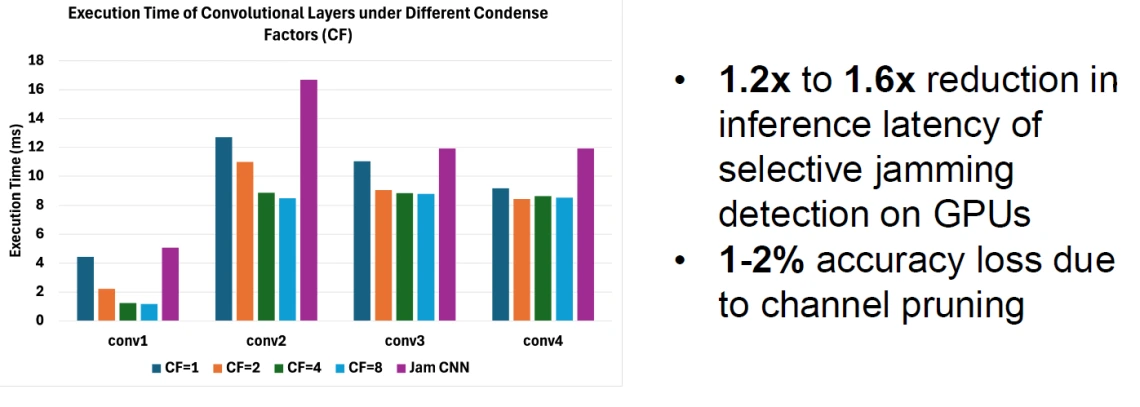
Next Steps:
- Performance modeling and optimization on PIM architecture
- End to end Pytorch to PIM compilation framework
- 3D Conv algorithms for multi-stage protocol classifiers
Thrust 3: Real-time ML-based Classifiers for Wireless Communications
Machine learning (ML) based signal classification plays several important roles in current and future (NextG) wireless systems. One important use case relates to facilitating coexistence of heterogeneous technologies over shared spectrum, including, for example, the CBRS band (3.55-3.7 GHz), the recently auctioned 3.45-3.55 GHz band, the unlicensed 5 and 6 GHz UNII bands, as well as various other swaths of mid-band spectrum from 1 GHz to 12 GHz. In addition to Wi-Fi, LTE, and 5G/FR1, incumbents of the mid-band include radar, radio-astronomy telescopes, aviation systems (e.g., altimeters), fixed microwave, intelligent transportation systems (ITS), and others. Policymakers are considering opening up the 3.1-3.45 GHz band, currently allocated to stationary, mobile, and airborne federal radar, for secondary use by commercial operators. ML-based classification is not limited to mid-bands; it also extends to high bands, including mmWave and sub-THz bands above 95 GHz, which are a cornerstone for NextG systems, but must be shared with passive systems such as sensing satellites and radioastronomy telescopes. The heterogeneity of coexisting systems implies that spectrum access cannot be coordinated through one common protocol. This motivates the need for signal classification as a means of identifying the types and features/parameters of heterogeneous transmissions over different segments of the spectrum.
Another important use case of ML-based signal classification is related to securing wireless systems against stealthy adversarial attacks, including selective jamming and impersonation. Securing such systems require the ability to detect and classify adversarial, anomalous, rogue, and mimicked transmissions, and extracting on-the-fly key features of such transmissions for subsequent analysis and neutralization/isolation. For instance, an ML classifier can be used to extract salient features of an otherwise unknown signal, including periodic patterns, spectral footprint, and modulation type, and accordingly determine the threat level of this signal (e.g., whether it is trying to selectively jam certain control channels). Attackers may also try to mimic a legitimate control signal, such as a synchronization or a timing signal, aiming to trigger a certain response from legitimate nodes. Identification of such mimics is crucial to the overall security of the network.
The focus of Thrust 3 is on the design of ML classifiers for real-time signal inference and identification and while considering the limited energy and computational capabilities of edge devices. Real-time inference is particularly important in wireless scenarios where the signal of interest is captured and processed on the fly. The stringent latency requirement poses a serious implementation challenge that necessitates innovative hardware, software, and algorithmic designs to preprocess the incoming signal from the RF frontend at 100’s of mega-samples/second, segment them into windows, transform each window into an appropriate input format (e.g., spectrogram or a scalogram), and feed this formatted input to the classifier. The problem is accentuated when a multi-stage (hierarchical) classification network is used (see figure below), whereby a first-stage classifier is tasked with identifying one aspect of the signal (e.g., its underlying protocol or jamming type), followed by one or more stages of classifiers that identify other aspects, such as modulation type, jamming sub-type, or other abnormalities.
Applications in Multi-stage Wireless Signal Inference
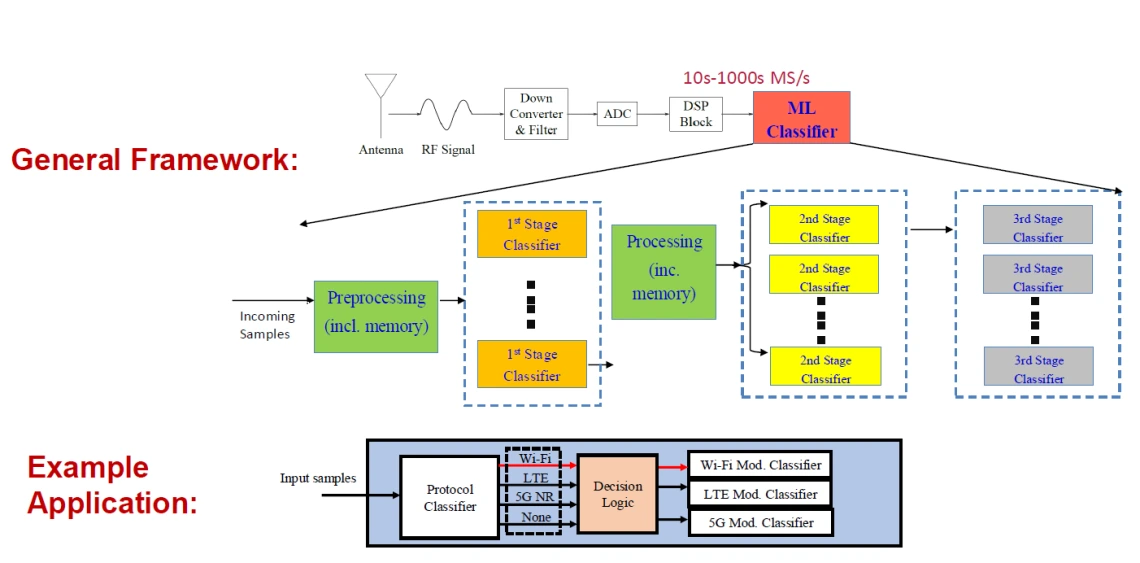
Sample Results:
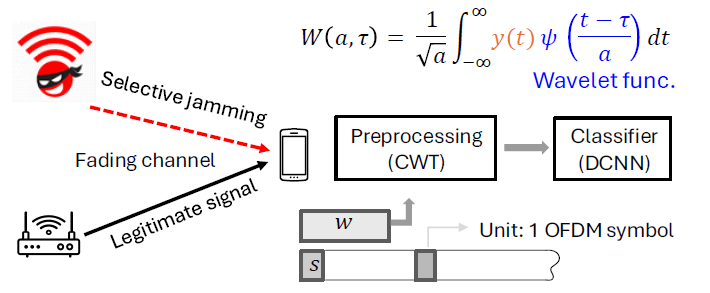 As part of this thrust, we consider the problem of detecting selective jamming attacks on IEEE 802.11ac Wi-Fi networks. The figure to the right presents the overall framework for detecting and classifying smart jamming in Wi-Fi networks using time-frequency features and deep learning. The system model consists of a legitimate Wi-Fi transmitter-receiver pair and an adversary, whose goal is to launch smart jamming attacks against the legitimate signal. The jamming is injected selectively during transmission, and we define the Signal-to-Jamming Ratio (SJR) as the power ratio between the legitimate signal and the jamming signal at the receiver while the jamming is active. The defender residing at the receiver has no prior knowledge about whether jamming is present or what type of jamming it might be. Instead, it samples the received baseband I/Q signals and applies a two-stage pipeline: signal preprocessing followed by classification. In the preprocessing stage, the Continuous Wavelet Transform (CWT) is applied to short, partially overlapping I/Q segments using a sliding window across OFDM symbols, producing high-resolution scalograms that capture both spectral and temporal characteristics of the signal. These scalograms are directly fed into a lightweight deep convolutional neural network (DCNN₁) that is trained to detect and identify the type of jamming without resizing or cropping the input, preserving the integrity of time-frequency features.
As part of this thrust, we consider the problem of detecting selective jamming attacks on IEEE 802.11ac Wi-Fi networks. The figure to the right presents the overall framework for detecting and classifying smart jamming in Wi-Fi networks using time-frequency features and deep learning. The system model consists of a legitimate Wi-Fi transmitter-receiver pair and an adversary, whose goal is to launch smart jamming attacks against the legitimate signal. The jamming is injected selectively during transmission, and we define the Signal-to-Jamming Ratio (SJR) as the power ratio between the legitimate signal and the jamming signal at the receiver while the jamming is active. The defender residing at the receiver has no prior knowledge about whether jamming is present or what type of jamming it might be. Instead, it samples the received baseband I/Q signals and applies a two-stage pipeline: signal preprocessing followed by classification. In the preprocessing stage, the Continuous Wavelet Transform (CWT) is applied to short, partially overlapping I/Q segments using a sliding window across OFDM symbols, producing high-resolution scalograms that capture both spectral and temporal characteristics of the signal. These scalograms are directly fed into a lightweight deep convolutional neural network (DCNN₁) that is trained to detect and identify the type of jamming without resizing or cropping the input, preserving the integrity of time-frequency features.
|
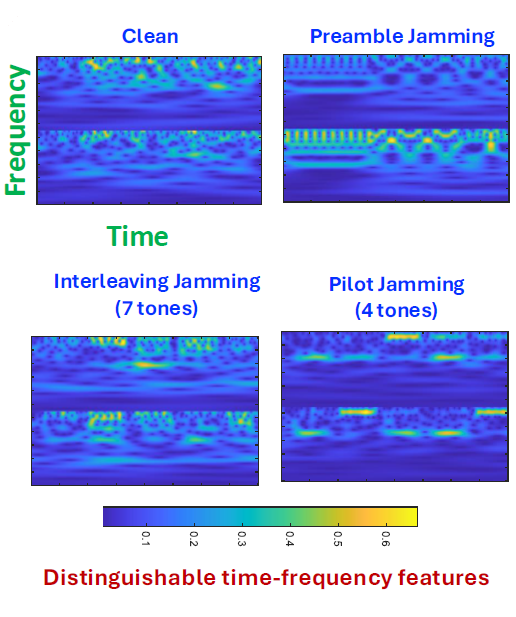
The figure to the right depicts representative scalograms produced by the Morlet wavelet for four signal conditions: clean, preamble jamming, interleaving jamming (7 tones), and pilot jamming (4 tones). The x-axis is the time, while the y-axis is the frequency. In the absence of jamming, the energy distribution is low and dispersed across the entire time-frequency plane. However, due to preamble jamming, the energy distribution aligns with the periodicity of the preamble in the time domain and extends over a broad frequency range. In contrast, interleaving jamming displays high-energy concentrations across several frequencies in two separate domains. Lastly, pilot jamming causes the scalogram to exhibit persistent high energy around four frequency components, extending over time. |
|
|
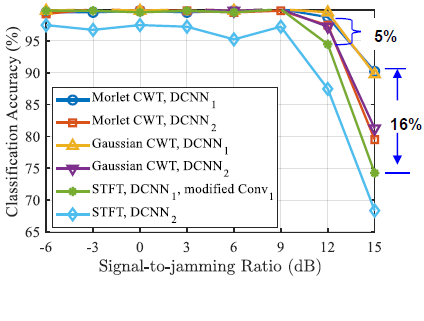
The performance plot on the right compares classification accuracy across a range of SJRs from –6 dB to +15 dB for different combinations of preprocessing and model architectures. To study the impact of different wavelets, Morlet wavelets are compared with Gaussian derivative wavelets using the same DCNN₁ model, and there is no observable performance gap between the two, and the accuracy at 15 dB SJR is 90%. When a simplified DCNN₂ model is used by removing early convolutional layer, the accuracy drops by approximately 10% at an SJR of 15 dB. Using Short-Time Fourier Transform (STFT) instead of CWT for preprocessing performs comparably to CWT only up to 9 dB SJR, but beyond that, the accuracy degrades significantly and drops by up to 16% compared to CWT at 15 dB SJR. Moreover, when STFT is paired with the simplified DCNN₂, the classification performance further deteriorates. |
|
Representation Publications
- Ayushi Dube, Gian Singh, and Sarma Vrudhula, "A compact, low power transprecision ALU for smart edge devices," accepted to appear in the Proc. of the IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED) Conference, University of Iceland, Iceland, August 2025.
- Gian Singh and Sarma Vrudhula, "A scalable and energy-efficient Processing-in-Memory architecture for Gen-AI," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 15, no. 2, pp. 285-298, June 2025, doi: 10.1109/JETCAS.2025.3566929.
- Gian Singh, Ayushi Dube, and Sarma Vrudhula, "A high throughput, energy-efficient architecture for variable precision computing in DRAM," Proc. of the IFIP/IEEE 32nd International Conference on Very Large Scale Integration (VLSI-SoC), Tanger, Morocco, 2024, pp. 1-6, doi: 10.1109/VLSI-SoC62099.2024.10767834.
- Md Rabiul Hossain and Marwan Krunz, "PCI classification in 5G NR: Deep learning unravels synchronization signal blocks," Proc. of the IEEE SECON Conference, Dec. 2024.
- Wenhan Zhang, Meiyu Zhong, Ravi Tandon, and Marwan Krunz, "Filtered randomized smoothing: A new defense for robust modulation classification," Proc. of the IEEE MILCOM Conference, Oct. 2024.
- Zhiwu Guo, Chicheng Zhang, Ming Li, and Marwan Krunz, "Fair probabilistic multi-armed bandit with applications to network optimization," IEEE Transactions on Machine Learning in Communications and Networking (TMLCN),vol. 2, pp. 994-1016, June 2024, doi: 10.1109/TMLCN.2024.3421170.
- Arush S. Sharma and Marwan Krunz, "Enhanced RFI detection in imbalanced astronomical observations using weakly supervised GANs," Proc. of the IEEE ICC Conference - Workshop on Catalyzing Spectrum Sharing via Active-Passive Coexistence, Denver, June 2024.
- Li, Changxin, and Sanmukh Kuppannagari, "Exploring algorithmic design choices for low latency CNN deployment," Proc. of the IEEE 31st International Conference on High Performance Computing, Data, and Analytics (HiPC), 2024.
- Cronin, Timothy L., and Sanmukh Kuppannagari, "A framework to enable algorithmic design choice exploration in DNNs," Proc. of the IEEE High Performance Extreme Computing Conference (HPEC), 2024.